Scaling the Boring Stuff: Sending 10 Million Notifications with a Simple Node.js Job Worker
Queues, backpressure, idempotency, and rate limits explained the way production systems actually behave

Principal Technical Consultant at GeekyAnts.
Bootstrapping our own Data Centre services.
I lead the development and management of innovative software products and frameworks at GeekyAnts, leveraging a wide range of technologies including OpenStack, Postgres, MySQL, GraphQL, Docker, Redis, API Gateway, Dapr, NodeJS, NextJS, and Laravel (PHP).
With over 9 years of hands-on experience, I specialize in agile software development, CI/CD implementation, security, scaling, design, architecture, and cloud infrastructure. My expertise extends to Metal as a Service (MaaS), Unattended OS Installation, OpenStack Cloud, Data Centre Automation & Management, and proficiency in utilizing tools like OpenNebula, Firecracker, FirecrackerContainerD, Qemu, and OpenVSwitch.
I guide and mentor a team of engineers, ensuring we meet our goals while fostering strong relationships with internal and external stakeholders. I contribute to various open-source projects on GitHub and share industry and technology insights on my blog at blog.faizahmed.in.
I hold an Engineer's Degree in Computer Science and Engineering from Raj Kumar Goel Engineering College and have multiple relevant certifications showcased on my LinkedIn skill badges.
At scale, notifications are not special. They are just one of the most common million job problems you will ever solve.
Email, SMS, WhatsApp, and app notifications all share the same pain points. External providers enforce limits you do not control. Jobs fail midway. Retries happen. Throughput fluctuates. If your system ignores these realities, it will eventually break in loud and expensive ways.
This post walks through a simple, reusable Node.js worker pattern for processing millions of notification jobs safely. Notifications are the example, but the same design works for data pipelines, webhooks, background processing, and batch workloads.
No frameworks. No theory heavy definitions. Just patterns that survive production.
Notifications are just jobs with consequences
When someone says “send 10 million notifications”, what they really want is:
jobs processed eventually
no duplicate sends
controlled throughput
safe retries
predictable failure handling
Email, SMS, and messaging providers just punish mistakes faster than most systems. That is why notifications make such a good example.
The core idea is simple.
Sending a notification is not a function call.
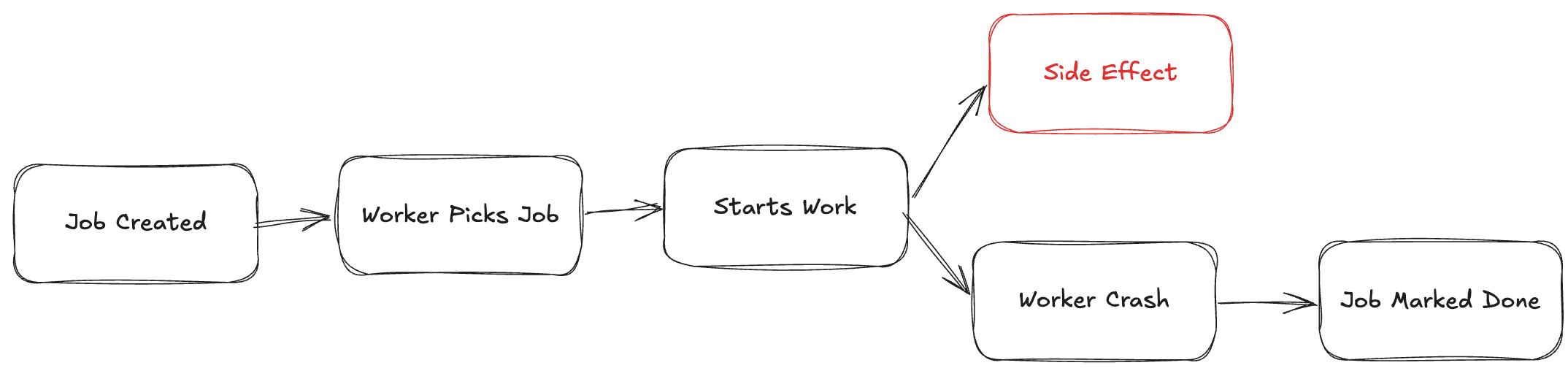
It is a job that moves through states.
The basic architecture
The system has four boring parts:
API that creates notification jobs
Queue that holds job IDs
Workers that process jobs
A datastore that tracks job state
The API never sends notifications. It only enqueues work.
This separation is what allows the system to scale without lying to users.
A reusable Node.js worker pattern
Below is a minimal worker pattern that works for email, SMS, WhatsApp, push notifications, or any other background job.
No frameworks. Just Node.js.
// worker.js
const MAX_CONCURRENCY = 10
const RATE_LIMIT_PER_SECOND = 50
let active = 0
let tokens = RATE_LIMIT_PER_SECOND
setInterval(() => {
tokens = RATE_LIMIT_PER_SECOND
}, 1000)
async function fetchJob() {
// pull one job ID from queue
}
async function loadJob(jobId) {
// load job record from DB
}
async function markState(jobId, state, meta = {}) {
// update job state in DB
}
async function processJob(job) {
// send email, SMS, WhatsApp, push notification, etc
}
async function workerLoop() {
if (active >= MAX_CONCURRENCY || tokens <= 0) {
return
}
const jobId = await fetchJob()
if (!jobId) return
active++
tokens--
try {
const job = await loadJob(jobId)
if (job.state === "completed") {
return
}
await markState(job.id, "processing")
await processJob(job)
await markState(job.id, "completed")
} catch (err) {
if (err.retryable) {
await markState(jobId, "queued")
} else {
await markState(jobId, "failed", { reason: err.message })
}
} finally {
active--
}
}
setInterval(workerLoop, 10)
This single pattern gives you:
controlled concurrency
built in rate limiting
safe retries
idempotent execution
Nothing fancy. Very hard to break.
Idempotency is not optional
Retries will happen. Crashes will happen. Deploys will interrupt jobs.
Without idempotency, retries mean duplicate notifications. Duplicate SMS or WhatsApp messages are not just annoying, they are expensive.
Every job must have a unique key that represents the work, not the attempt.
For notifications, a good key looks like:
notificationType + templateVersion + userId + channel
Before processing, check if this key already completed.
If yes, skip.
If no, proceed.
Exactly once delivery is a myth.
Exactly once effects are achievable.
Backpressure keeps your system and providers alive
Backpressure means slowing down when downstream systems struggle.
In practice:
reduce concurrency when error rates rise
stop pulling from queue when retries spike
throttle globally when providers respond slowly
If your workers keep running at full speed during throttling, you are not scaling. You are burning reputation.
A rising queue is not failure.
Ignoring it is.
Job state beats logs every time
Logs help debug. They do not help operate.
Store explicit states:
queued
processing
completed
failed
This allows:
safe restarts
replaying failures
accurate dashboards
real progress tracking
Logs explain the past.
State controls the present.
Dead letter queues need exits
Some notification jobs will never succeed:
invalid phone numbers
blocked email domains
users who opted out
malformed payloads
Move them to a dead letter queue with:
reason
payload
timestamp
And most importantly: replay support.
A dead letter queue without replay is just data loss with better branding.
Real world rate limits you will hit
AWS SNS
Publish rate depends on region and account
Typical defaults are a few hundred messages per second
Fanout helps, but downstream systems still apply limits
SNS is good at distribution, not protection.
AWS SQS
Standard queues scale extremely well
Practically unlimited throughput
Ordering is not guaranteed
Visibility timeouts matter more than rate limits
SQS absorbs load. It does not enforce safety.
AWS SES
Strict per second and per day quotas
New accounts start with very low limits
Throttling affects deliverability silently
SES is unforgiving if you spike too fast.
If AWS is not your option
Common alternatives and their realities:
RabbitMQ: great control, you own scaling and backpressure
Kafka: massive throughput, higher operational cost
Postgres queues: surprisingly good for many teams
Redis streams: fast, but memory bound
Notification providers like Twilio, SendGrid, Mailgun, Postmark, WhatsApp APIs all enforce:
per second limits
per sender reputation
aggressive throttling on spikes
No provider lets you brute force scale.
Why this pattern works everywhere
This worker pattern works because it accepts reality:
failures are normal
retries are required
limits exist
speed is negotiated, not demanded
Once you build this, notifications become boring again.
And boring systems are the ones that scale.
Closing
Scaling is not about sending faster. It is about finishing safely.
Queues buy time.
Backpressure buys trust.
Idempotency buys sleep.
Do these three well, and processing millions of notifications becomes just another day at work.