Retries Are Not a Fix. They Are a Liability.
Most retry mechanisms in background jobs are unsafe by default. This is a quick way to find out if yours is one of them.

Principal Technical Consultant at GeekyAnts.
Bootstrapping our own Data Centre services.
I lead the development and management of innovative software products and frameworks at GeekyAnts, leveraging a wide range of technologies including OpenStack, Postgres, MySQL, GraphQL, Docker, Redis, API Gateway, Dapr, NodeJS, NextJS, and Laravel (PHP).
With over 9 years of hands-on experience, I specialize in agile software development, CI/CD implementation, security, scaling, design, architecture, and cloud infrastructure. My expertise extends to Metal as a Service (MaaS), Unattended OS Installation, OpenStack Cloud, Data Centre Automation & Management, and proficiency in utilizing tools like OpenNebula, Firecracker, FirecrackerContainerD, Qemu, and OpenVSwitch.
I guide and mentor a team of engineers, ensuring we meet our goals while fostering strong relationships with internal and external stakeholders. I contribute to various open-source projects on GitHub and share industry and technology insights on my blog at blog.faizahmed.in.
I hold an Engineer's Degree in Computer Science and Engineering from Raj Kumar Goel Engineering College and have multiple relevant certifications showcased on my LinkedIn skill badges.
Before you read, run this test
If you’re using background jobs, queues, or retries, answer this:
If the same task runs twice, does anything break?
Can you tell if the task already completed before retrying it?
Does every retry carry the correct user / tenant context?
Do you mark tasks as done only after confirming the outcome?
Can you trace what happened across retries?
If you answered “no” to 2 or more: Your retries are unsafe.
If you answered “no” to 3 or more: Your system will eventually corrupt data.
Why this test exists
We added retries to a system recently.
Error rates dropped. Dashboards looked better.
But a few days later:
duplicate emails started showing up
duplicate operations increased
and in one case, a user from tenant A received an email meant for tenant B
Nothing was failing anymore.
But nothing was correct either.
Why retry mechanisms fail in real systems
A retry is not:
“try again”
A retry is:
“run the same operation again, even if we don’t know what already happened”
That uncertainty is where systems break.
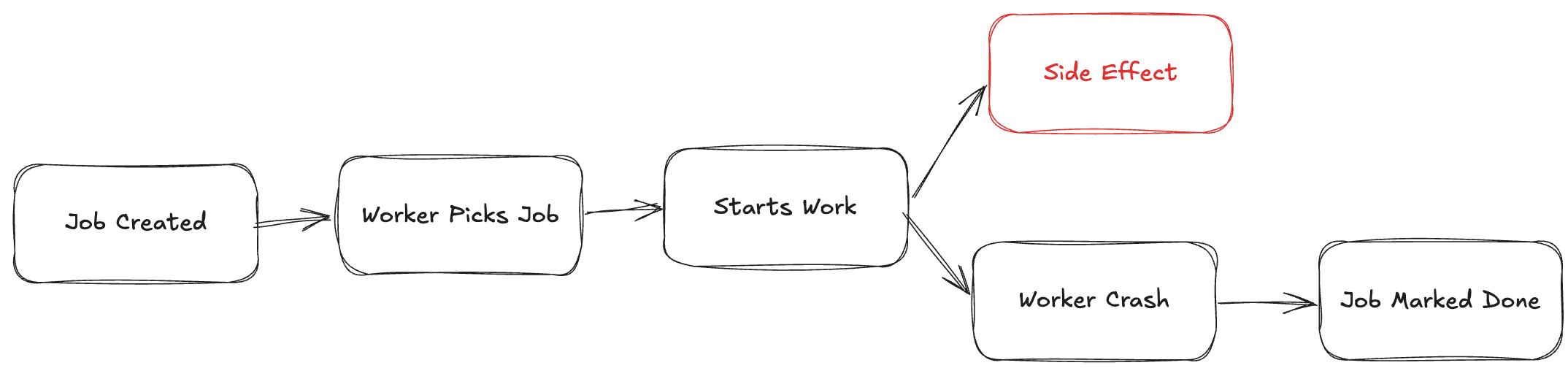
What actually happens in distributed systems
In real systems:
API call succeeds but response is lost
Database write happens but worker crashes
External service processes request but times out
Your system sees a failure.
Reality has already moved forward.
Now the retry runs.

The system retries because it thinks nothing happened. Reality says otherwise.
This is how systems quietly break
Payment gets charged twice
Email gets sent multiple times
Inventory gets updated incorrectly
Retries don’t fix failures.
They repeat them.
It gets worse in multi-tenant systems
We reviewed a system where a user from tenant A received an email meant for tenant B.
No errors. No alerts.
What happened:
Job had tenant context
Worker partially failed
Retry ran without proper isolation
Same job executed with wrong tenant context
Now it wasn’t just a duplicate.
It was a data leak.
A retry without tenant isolation is not a retry. It’s a cross-tenant bug.
The real mistake
Most systems assume:
failure means nothing happened
That assumption is wrong.
The most dangerous state is:
something happened, but you don’t know if it did
Retries operate blindly in that state.
How to design safe retries in distributed systems
Retries are fine.
Blind retries are not.
1. Make operations idempotent
If the same job runs twice, the result should not change.
No idempotency → no safe retries.
2. Treat retries as duplicate executions
Not second chances.
Design every job assuming:
it may run more than once
3. Don’t mark success too early
Only mark a job complete after:
the side effect is confirmed
4. Preserve context explicitly
Especially in multi-tenant systems:
tenant ID must be part of job identity
never rely on implicit or global state
retries must carry full context
A safer retry pattern
If you take one thing from this post, use this:
// 1. Check if operation already exists
// 2. If yes → exit
// 3. Perform side effect
// 4. Store result with unique operation ID
// 5. Mark job complete
This gives you:
safe retries
crash recovery
duplicate protection
Where most NestJS setups go wrong
This is common with Bull/BullMQ:
@Process()
async handle(job: Job) {
await this.paymentService.charge(job.data)
}
Looks fine. Breaks with retries.
Safer version:
@Process()
async handle(job: Job) {
const exists = await this.repo.find(job.id)
if (exists) return
const result = await this.paymentService.charge(job.data)
await this.repo.save({
jobId: job.id,
status: 'completed',
result
})
}
Retries now don’t duplicate work.
Summary
Retries repeat operations, they don’t fix failures
Most systems cannot safely handle duplicate execution
Idempotency is required for reliable background jobs
Context loss in retries can lead to data leaks
Reliability comes from design, not retries
Closing
If retries can break your system, your system was already broken.
In multi-tenant systems, they don’t just break things.
They leak them.
Final line
Failures are visible.
Retries make them invisible.
That’s why they are dangerous.